
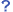

日本語と文字コード
コンピュータは主にアメリカで発達してきたため、未だにアルファベットや数字などの1バイト(7/8ビット)を基本単位として扱う前提で作られているものが中心です。そのなかで日本語のように多くの文字を必要とする言語は、1文字を表わすのに2バイト以上を要するため、いろいろな困難が伴います。特にインターネットを通じて様々な環境の情報を交換するにあたって、思わぬ問題に遭遇するケースが増えてきました。ここでは、こうしたことを考えるために必要な、日本語の文字コードに関する基本を整理しておきます。
JIS漢字コード(情報交換用符号化漢字集合)
JIS漢字コードは「図形文字とそれらのビット組合せとの対応を規定する」規格であるとされています。1978年1月1日に最初のものが発表され(JIS C 6226-1978)、1983年の改訂を経て(一部の漢字を追加したり入れ替えたりして*注1)1990年9月のJIS X 0208-1990によって現在の6,879文字の“漢字集合”が定められました。
このX 0208は1997年1月に再度改訂され、従来曖昧だった部分をより厳密にするとともに、シフトJISやRFC1468などの符号化法もJISに取り込みました(JIS X 0208:1997)。
この規格は正式には「7ビット及び8ビットの2バイト情報交換用符号化漢字集合」と呼ばれ、図形文字の集合(文字セット)として6,879文字が定められています。このうち、かなや記号を除いた漢字は6,355字で、使用頻度に応じて第一水準と第二水準にわけられています。
使用頻度の高い第一水準は2,965字あり、基本的に音読みの50音順に並んでいます(音読みのないものや複数の読みのあるものは一つを「代表音訓」と定めてそれによって並べる)。第二水準は頻度はそれほど高くないが重要なものと、人名などによく使われる旧字体が3,390字選ばれ、こちらは漢和辞典のように部首順(部首内では画数順)に並べられました。
さらに、1990年10月には6,067文字の補助漢字文字セット(JIS X 0212-1990)が制定されました。この文字セットとJIS X 0208-1990を合わせれば12,946(うち漢字は12,156)の標準文字が使えることになりますが、この補助漢字をサポートする製品はほとんどないのが実状です。
〔補足〕MacOS 8、Windows98では補助漢字(X 0212)に相当する文字が標準フォントセットに組み込まれ、Unicodeとしてこれらの文字を扱っているが、次に述べるJIS X 0213との関係がどうなるかなど、まだ課題は多そうだ。
2000 JIS (X 0213)
1997 JIS(X 0208:1997)の公開後、引き続き検討されてきたJIS漢字コードの拡張(第三水準及び第四水準)が、2000年1月20日にJIS X 0213:2000として制定されました。X 0213はX 0208の6,879文字にさらに4,344文字を追加して合計11,223字が規定されています。この追加により、従来は「機種依存文字」とされていた○付数字や、JIS批判の標的になっていた人名漢字の多くが正式な規格になりました (ただし、以前このページで「含まれることになった」と記述していた「はしご高」は、含まれていません。お詫びして訂正します)。
ただ、この規格がパソコンなどに実装されるには、Unicodeとの関連もあってしばらく時間がかかると見られています。アップルコンピュータは、次期OSのMacOS Xで2000JISに対応した新フォントを搭載し、Unicodeに登録された文字から順次収録するとしています。
〔補足〕
2000JISに関しての補足を追加する時間がないので、仕組みについて
などを参照してください。また、背景を知るには、Internet Watchに連載されている
が興味深いです。
〔以上補足〕
区点コード
区点コードはJIS X 0208-1990とJIS X 0212-1990の規格書で文字を分類配列している表(図形文字符号表*注3)での位置を示す番号です。ここでは94 x 94のマトリックス(*注4)を描き、その8,836の升目の中に文字コードを配しています。つまり、区とはこのマトリックスのY軸、点とはX軸に相当すると思えばよいでしょう。JIS X 0208-1990の文字種を区点コードの区分によって分類すると次のようになります:
| 区 | 文字数 | 文字種 |
|---|---|---|
| 1-2 | 147 | 各種記号 |
| 3 | 62 | 数字、ローマ字 |
| 4 | 83 | ひらがな |
| 5 | 86 | カタカナ |
| 6 | 48 | ギリシャ文字 |
| 7 | 66 | キリル文字 |
| 8 | 32 | 罫線素片 |
| 9-15 | 0 | 未定義 |
| 16-47 | 2965 | 第一水準 |
| 48-84 | 3390 | 第二水準 |
| 85-94 | 0 | 未定義 |
各区には最大94文字を割り当てることができます。区点コードは例えば第6区の第46点(JIS X 0208-1990では「ξ」)ならば06-46と、区と点を2桁の10進数で表して並べたもの。この文字を実際に符号化する場合は、以下で述べる3つの方法によって対応する数値コードは異なり、JISなら264E、ShiftJISなら83CCなどという具合になります。
〔補足〕JIS X 0213では94 x 94の表を2つ持つ構成となり、それぞれを1面、2面と呼びます。従って、X0213の場合は「面区点番号」を使うことになるわけです。
JISコード(符号化方式)
ここで、文字集合とその符号化方式を区別しておきましょう。
- 文字集合(文字セット)とは「含まれる文字を明示した集まり」です。例えば、常用漢字というのも文字集合の規格の一つですし、中国語や韓国語にはそれぞれの文字セット規格があります。
- 符号化方式とはそれらの文字を「どのように数値コード(ビット組合せ)に対応させるか」というルールです。日本語の符号化方式は一般にJIS、シフトJIS、EUCの3つが用いられ、統一されていません。
- さらに文字コードとは、JIS X 0202によれば「文字集合を定め、かつその集合内の文字とビット組合せを1対1に関係づける、あいまいでない規則の集合」ということになります(JISでは「符号化文字集合」と呼んでいます)。
 いわゆるJISコードは、JIS X 0208の漢字集合(文字セット)の各バイトを0x21〜0x7Eの領域(GLと呼ばれます)に割り当てた7ビット符号方式(*注6)による文字コードです 〔X 0208:1997 規格票7.1〕 。
いわゆるJISコードは、JIS X 0208の漢字集合(文字セット)の各バイトを0x21〜0x7Eの領域(GLと呼ばれます)に割り当てた7ビット符号方式(*注6)による文字コードです 〔X 0208:1997 規格票7.1〕 。
また、これに国際的な符号拡張方式 (ISO/IEC 2022-1993、日本語訳はJIS X 0202-1991 ) を適用することで、1バイトのASCIIあるいはJISローマ字とともに用いることができます。
この拡張法はきちんと定義するとかなり複雑なものですが、インターネットの電子メールで用いられるJISコード( ISO-2022-JPもしくはJUNETコード) は、このサブセットを使って簡略化した形(*注5)で符号化を行なっています( RFC1468。また1997年のX 0208:1997〔附属書2〕において、JIS規格にも取り込まれた)。
使用する文字集合は「エスケープシーケンス」と呼ばれる特殊な文字列を目印にして切り替えます。JISコードで用いるエスケープシーケンスは4とおり:
| 3文字のシーケンス | 切り替えられる文字コード |
| [ESC] ( B | ASCII |
| [ESC] ( J | JISローマ字 |
| [ESC] $ @ | JIS-1978 |
| [ESC] $ B | JIS-1983 |
([ESC]とは0x1Bという値を持つ特殊キャラクタ *注7)。
〔補足〕JIS X 0213附属書2のIS0-2022-JP-3符号化表現では、[ESC] $ ( Oというエスケープシーケンスで1面の漢字集合に、[ESC] $ ( Pで2面に切り替えることになっています。
〔補足〕JISにおける1バイト仮名(いわゆる半角カナ*注8)の符号化は、8ビット目を用いて10進数の161〜223(0xA1〜0xDF)の範囲に割り当てる方法(JIS8)と、7ビットだけでエスケープシーケンスやSO/SIによって半角カナモードに切り替える方法(JIS7)があります(JIS X 0201)。いずれもそれほど広くサポートされているわけではなく、いろいろなトラブルの元にもなるため、インターネット電子メールの場合は半角カナは使用しないのが原則です。
シフトJISコード
シフトJISは、現在パソコンの多くで使われている文字コードで、SJIS、MS漢字とも呼ばれます。これは1バイト仮名(X 0201)で未定義領域になっている部分を使って漢字(X 0208)を表現することで、エスケープシーケンスなしで1バイト文字と2バイト文字を共存できるようにしたものです。そのためにJISコードを移動(シフト)させたことからこう呼ばれます。
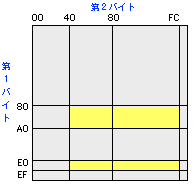 シフトJISでは、10進数の129〜159、224〜239(0x81〜0x9F、0xE0〜0xEF)の範囲のバイトが現れると2バイトモードが開始され、このバイトは2バイト文字の第1バイトとして処理されます。続く第2バイトは64〜126、128〜252(0x40〜0x7E、0x80〜0xFC)の範囲でなければなりません。第1バイトの範囲は、英数字(ASCII、0x21〜0x7E)や1バイト仮名(半角カナ、0xA1〜0xDF)と重複しないように配置されています。JISコードとは簡単なアルゴリズムで相互変換が可能です。
シフトJISでは、10進数の129〜159、224〜239(0x81〜0x9F、0xE0〜0xEF)の範囲のバイトが現れると2バイトモードが開始され、このバイトは2バイト文字の第1バイトとして処理されます。続く第2バイトは64〜126、128〜252(0x40〜0x7E、0x80〜0xFC)の範囲でなければなりません。第1バイトの範囲は、英数字(ASCII、0x21〜0x7E)や1バイト仮名(半角カナ、0xA1〜0xDF)と重複しないように配置されています。JISコードとは簡単なアルゴリズムで相互変換が可能です。
上記で分かるとおり、このシフトJISのコードは8ビット目も使用しているため、電子メールで流すときはJISコードに変換する必要があります。事実上日本で最も普及している文字コードであり、文字セット切り替えがないので扱いも簡単というメリットがありますが、コードが分断されており体系として不自然なため漢字処理に一家言を持つ人の間では嫌われているようです。
また、この方式ではJIS X 0212-1990の補助漢字文字セットを使う方法がないこと、ユーザー定義領域にメーカー独自の「外字」を割り当てたため、相互の情報交換やほかの方式への変換ができないケースがあるなどの問題も抱えています。
〔補足〕
もともとこれは文字セットのみJIS規格を用い、符号化はJISに基づかない独自の方式でしたが、1997年のX 0208:1997の〔附属書1〕において、「シフト符号化表現」として正式にJIS規格に取り込まれました。しかし、2000年のX 0213:2000においては、追加したコードを外字領域に割り当てて混乱を招く恐れが高いことから、この付属書は「規格」ではなく「参考」という扱いになっています。
なお、JIS X 0213では、第1バイトが0xF0〜0xFCの領域に第2面の漢字が割り当てられます。従来、外字領域として使われていた可能性のある場所を使うので、互換性の面で注意が必要になります。
〔以上補足〕
EUCコード
EUC (Extended Unix Code) は日本語対応UNIXワークステーションで内部コードとして広く使われています。日本語EUCもJISコードと同じくJIS 0208の文字セット規格をISO 2022-1993に基づいて符号化します(*注5)。EUC自身は、日本語だけでなく複数の文字セットを同じテキスト内で処理することが可能です。
EUCには可変長コードと固定長コードの2とおりありますが、一般的なのは可変長(圧縮フォーマット)の方です。詳しい説明は省略しますが、簡単に言って4とおりの文字セットが使い分けられます。
| セット | 第1バイト | 第2バイト | 第3バイト | 日本語EUCの場合 |
| G0 | 0x21〜0x7E | - | - | ASCII |
| G1 | 0xA0〜0xFF | 0xA0〜0xFF | - | JIS X 0208-1990(新JIS) |
| G2 | 0x8E | 0xA0〜0xFF | - | JIS X 0201カナ(1バイト仮名) |
| G3 | 0x8F | 0xA0〜0xFF | 0xA0〜0xFF | JIS X 0212-1990(補助漢字) |
ASCIIに相当する部分は1バイト(7ビット)で表現されます。0xA0〜0xFFの範囲の文字は、そのまま使われる場合は2バイト合わせてJIS X 0208の漢字(JISコードの8ビット目を1にしたもの)を表します。1バイト仮名は0x8Eという特別な制御文字(SS2)に続いて1バイトの文字コードを割り当てます。0x8Fという制御文字(SS3)はその後ろに2バイトの文字コードをとりますが、このセットは一般に補助漢字に割り当てられます。
〔補足〕JIS X 0213では、SS3によって呼び出すG3には、補助漢字ではなくX0213の第2面の漢字が割り当てられます。
ASCIIとJISローマ字
 ASCIIとはAmerican Standard Code for Information Interchangeの頭文字を取ったもので、規格の定義はISO 646-1991に記載されています。これは7ビット128文字で構成され、94文字がアルファベット、数字、記号などの印刷可能な文字、残り34文字は空白文字と制御記号に割り当てられています。
ASCIIとはAmerican Standard Code for Information Interchangeの頭文字を取ったもので、規格の定義はISO 646-1991に記載されています。これは7ビット128文字で構成され、94文字がアルファベット、数字、記号などの印刷可能な文字、残り34文字は空白文字と制御記号に割り当てられています。
このASCIIを拡張して8ビットを使い、ほかの欧州言語で用いるアクセント記号付きの文字やキリル文字、アラビア文字などを表せるようにした拡張ASCII文字セットが1987〜1989年にかけて定義されました(ISO 8859)。これは第1部から第9部までの9種類あり、それぞれラテン系の文字やキリル文字、アラビア文字などが扱えるようになっていますが、実際に使用されるのはほとんど第1部として定義されているLatin-1(ISO 8859-1)のみです。
ローマ字の大部分はASCIIの文字セットと同じですが、ISO 646が独自割り当てを認めている範囲で、バックスラッシュ(半角の\)が円記号(\)に、ティルダ(〜)がオーバースコア( ̄)に入れ替えられています。この文字セットはJIS X 0201-1976で定義されています。なお、この規格では1バイト仮名63文字(JIS7 / JIS8の2方式)も合わせて定義されました。
Unicode
国際標準とUnicode
国際標準化機構(ISO)は、世界中の主要な文字を一括して扱う多重言語文字セット規格UCS (Universal multi-octet coded Character Set)を1993年に制定しました。これがISO/IEC 10646と呼ばれるもので、4バイトによる方式と2バイトによる方式の2通りがあります。もともとこれは各国の国内規格との互換性を考慮したものとして考えられていたのですが、一方で、アメリカのコンピュータ・メーカーを中心とするUnicodeコンソーシアムがこれとは異なる、16ビットで従来方式とは互換のない統一コードUnicodeを打ち出してきました。国際標準が2つできてしまうのは非常に具合が悪いので、両者が歩み寄る形で、ISOの当初の案を変更して新しい標準を制定することになったのです。
UnicodeはUCSの2バイト方式によるもので、256×256の升目を持つ二次元空間(Basic Multilingual Plane=BMPと呼ばれる)に65,536文字を割り当てることができます。
Unicodeと漢字
ここでは詳しい説明は省略しますが、この中に中国語、日本語、韓国語(頭文字を取ってCJKと称される)の漢字2万文字あまりを配置します。それに当たっては、各国で用いられている漢字コード(全部を合わせると12万以上になる)から重複するものや意味、構造が同じものを統合し、まとめていくHan Unificationという作業が行われました(これについては厳しい批判があります)。日本の文字コードとしてはJIS X 0208-1990とJIS X 0212-1990がサポートされます。
ごく大まかに言えば、Unicodeにおける漢字の表現は、第1バイトを0x4E〜0x9F(I領域)に割り当てたものです(第2バイトは0x00〜0xFFの全領域)。JISコードとの規則的な変換ルールは存在しないので、個々の文字を対応させる変換表が必要になります。
Unicodeは16ビット固定なので、文字列の操作が単純になります(と宣伝されていますが、実際はいろいろ変則的なつぎはぎがあって、そうはいかないようです)。2.0では38,885文字が割り当てられ、これらのコードポイントは永久的なアドレスとして信頼すべきものと(Unicodeの主張では)されています。一方、Unicodeでは従来の文字コードで想定されていたソートが保証されません。
Unicodeを巡る環境
Windows NTやMacOS 8など内部コードとしてUnicodeをサポートするという環境も出始め、JavaはUnicodeをデフォルトのデータ型として定義しました。Webの世界でも、最新のブラウザは(モジュールの追加により)Unicodeを表示できるようになっていますし、HTML 4.0では基本文字セットをISO/IEC 10646とするなど、最近の展開は急速です。ISO/IEC 10646 (Unicode)は2001年末にパート2の制定が予定されており、ここにはJIS X 0213で規定された新しい漢字コードも追加するように申請が行われています。
この規格(ISO 10646)の日本語版はJIS X 0221-1995として発行されました。
- 拙著『プロフェッショナル電子メール』において、Unicodeの符号化などについて簡単に解説しています。
-
Unicodeの問題点については、 太田昌孝著『いま日本語が危ない−文字コードの誤った国際化』の第5章2節をオンラインで掲載した 文字コードはどうあるべきか、 またTRONの坂村健氏らによる 多言語テキスト処理に関するバーチャル・シンポジウム を参照。
主要コード規格のまとめ
| 種類 | 規格 | 概要 |
|---|---|---|
| 7/8ビット | ISO 646:1991 | 7ビットによる英数字、記号の定義 |
| ANSI X 3.4-1986 | ASCIIコード。ISO-646のInternational Reference Versionと同じ | |
| EBCDIC, EBCDIK | IBMがメインフレーム用として開発した独自の7ビットコード | |
| ISO 8859 | 8ビットの拡張ASCII。よく使われるのがPart1 (Latin 1) | |
| JIS X 0201-1997 | ISO 646と同じ英数字に半角カナを加えたJISローマ字。半角カナを7ビット領域に割り当て、切り替えて使うJIS7と、8ビット目を使うJIS8の2通りがある | |
| 16ビット以上 | JIS X 0208:1997 | JIS漢字コード。第1水準、第2水準からなる。1997改訂でシフトJISも定義に含まれた。 |
| JIS X 0212-1990 | X 0208に納められていない補助漢字 | |
| JIS X 0213:2000 | X 0208に大幅に文字を追加した次世代の漢字規格 | |
| ISO/IEC 10646-1 | 多言語を扱うための規格。32ビットによるUCS-4と16ビットによるUCS-2があるが、実質的にはUnicode 1.1を基にしたUCS-2のみが使われる | |
| Unicode 2.0 | Unicode Consortiumが開発し、ISO 10646への適用やコードの入れ替えなどを行ったもの | |
| JIS X 0221-1995 | ISO 10646の日本版。X 0201, X 0208, X 0212との対応表などの解説を付加したもの。 | |
| 符号拡張法 | ISO/IEC 2022:1994 | 複数の文字集合を切り替えて利用するための枠組み(エスケープシーケンス) |
| JIS X 0202-1991 | 基本的にISO 2022と同じ |
参考文献、リソース
- 日本規格協会『JISハンドブック 情報処理 用語・符号・データコード編』
- 芝野耕司編著『JIS漢字字典』、1997年、日本規格協会
- 川俣晶『パソコンにおける日本語処理/文字コードハンドブック』1999年、技術評論社
- ケン・ランディ『日本語情報処理』、1995年、ソフトバンク
- 太田昌孝著『いま日本語が危ない−文字コードの誤った国際化』、1997年、丸山学芸図書
- 伊藤英俊『漢字文化とコンピュータ』、1996年、中公PC新書
- 『日経バイト』1996年5月号特集「土台揺らぐ日本語処理」
- 『日経バイト』1997年7月号解説「課題を残す文字コード標準化」
- 古瀬幸広『考える道具−ワープロの創造と挑戦』、1990年、青葉出版
(特に第6章でJIS漢字コードの制定について詳しく記されている) - Unicode Evolves,BYTE, March 1997 (翻訳記事:『日経バイト』1997年6月号)
- 錦見美貴子、高橋直人、吉田智子ほか『マルチリンガル環境の実現〜X Window/Wnn/Mule/WWWブラウザでの多国語環境〜』、1996年、プレンティスホール・ジャパン
- 江藤淳、池澤夏樹、島田雅彦、紀田順一郎ほか『電脳文化と漢字のゆくえ−岐路に立つ日本語』、1998年、平凡社
- 『電脳文化と漢字のゆくえ』拾い読み by 池田証寿氏@北海道大学
- 「“漢字不足”に作家ら危機感−電子メディアの文字コード問題でシンポ」、朝日新聞1998年2月5日夕刊
- 漢字コードFAQ
- 国境の内なる文字たち − 日本語情報処理のための新たなインデックス作成の試み
- コンピュータの漢字コード - KANJI tutorial file
- 文字 by 守岡知彦氏@北陸先端科学技術大学院大学
- 安岡孝一氏のホームページ
- 全学ゼミ講義ノート・文字コード by 豊田英司氏@東京大学
- JIS漢字 by 池田証寿氏@北海道大学
- 文字コードの話 by 伊藤隆幸氏
- RFC1468(英文) / Japanese Character Encoding for Internet Messages
- RFC1554(英文) / ISO-2022-JP-2: Multilingual Extension of ISO-2022-JP
- 国語審議会に対する日本文藝家協会からの要望書
- コードのはなし:追補−情報処理語学文学研究会会報 第17号(1995年 7月22日) by 豊島正之
- 座談会「国境をこえる日本語の条件」GLOCOM NEWSLETTER Summer, 1996
注
- (1) JIS文字コードの入れ替え
-
JIS C 6626が1978年に発表された後、81年の常用漢字導入を受けて新しい漢字95字を第1水準に組み込むためJIS X 0208-1983が制定された。このとき、新字体と旧字体22文字が第1水準と第2水準の間で入れ替えられた(コード・ポイントの変更)。さらに、250字の字形が変更され、人名用漢字4字と非漢字71字が追加された。
1990年に再度見直しが行われ、今度は第2水準に2字の追加が行われたほか、145文字について字形が変更された。
こうした変更により、同じコードを使っても文書を作成した時期によって文字が異なるという混乱が生じている。 - (2) 1997 JIS改訂
-
文字コードの入れ替えなどで混乱したX 0208 (-1990)の問題を解決するために
- 符号化方式(いわゆるJISコード)を明確にする
- 空き領域の利用禁止の明確化
- 重複記号(全角と半角)の利用禁止の明確化
- 収容漢字の典拠の明確化
- 字形に関する包摂規準*(対応関係)の明確化
- シフトJISに関する規定を明文化する
- 合成文字(○付きの数字など)の使用を禁止する
などの方針で改訂作業が進められ、JIS X 0208:1997として改訂された。外字禁止の方向を明確にしたが、戸籍システムなど実用が先行する分野では、Unicodeをベースとして外字利用の使用を策定しようとするXKPなどがJISとは違う動きを見せている。
また、X 0212はシフトJISに収容できないという問題があるため、シフトJISでも利用できる(つまり現在の空き領域に割り当てる)約5000字の補助漢字を制定することが検討されている。これはUnicode (X 0221) との関係や、半角カナの扱いの点で大きな問題をはらんでいる。こちらについては JIS 漢字の拡張計画 を参照。
96年9月18日の朝日新聞は国語審議会がワープロ字体の問題を審議する第二委員会を設置し、97年末にも字体の基準の試案を公表、98年6月に文相に答申の見込みと伝えている。
また10月5日の日経夕刊の報道によれば、通産省は新しいJISを98年にも制定する。通産 省は今回新たにJISに追加する漢字コードを世界共通コードに取り入れるようISOに 提案、ISO規格とJIS規格の間でデータ交換に支障が出ないようにする考えだという。*注の注:これは「基準」ではなく「規準」という字を使います。http://member.nifty.ne.jp/shikeda/kijun2.htmに説明あり。
- (3) 図形文字符号表
-
JIS X 0208とJIS X 0212では、図形文字(視覚的な図形によって表される文字。漢字、ローマ字など印刷可能な文字のこと)の集合を定めた上で、94x94の表に割り当てている。この表では各文字の第1バイト、第2バイトともに1〜7のビットについて符号が定められ、第8ビットは実装方法(JIS X 0202による呼び出しの方法)によって変わるものとして定めていない。いわゆるJISコードではこの第8ビットを0とし、EUCでは第8ビットを1として符号化している。
- (4) 94文字
-
JISは7ビット128通りのコードのうち、ASCIIなどで制御コードとされている0x00〜0x20と0x7Fの34個を除いた94の符号を2つ(2バイト)組み合わせて1つの文字を表現する。その結果、文字セットは94 x 94 = 8,836の空間に配置されることになる。
- (5) ISO-2022とJISコード、EUCコード
-
JIS: ISO 2022(JIS X 0202)は、7ビットで各国の言語を表現できるようにするために、複数の文字セットを切り替えながら使用する拡張符号化方式を定めている。ここでは、G0〜G3という4つの集合を考え、使用する文字セットをそれぞれの集合に「指示(designate)」しておき、そのうち実際の文字表現に使用するものを「呼び出す(invoke)」するという手続きを踏むことで文字セットを切り替える。
これをいくつかの前提条件をつけることで簡略化し、G0に文字セットを「指示」するだけで切り替えるのがJISコードの符号化方式である。この切り替え(指示)に使われるのが、エスケープシーケンス。EUC: 同じISO 2022では8ビット系での拡張方式も定めている。基本は7ビットの場合と似ているが、表現に使用する図形文字表に左(GL)と右(GR)いう考え方が加わり、GRの図形表の文字は最上位ビット(第8ビット)を1にするといういう点が異なる。EUCはこれを利用して、G0にASCII、G1にJIS X 0208があらかじめ指示され、さらにGLにはG0(つまりASCII)、GRにはG1(つまりJIS漢字)が呼び出されているとすることで、エスケープシーケンス無しで、第8ビットが0ならASCII、1ならJIS漢字と使い分けられるようにした。さらにG2、G3に1バイト仮名、補助漢字をそれぞれ指示しておき、必要なときにSS2、SS3というシングルシフト機能(続く1文字=2バイト文字なら2バイト=だけその図形表をGRに呼び出す)を用いることで切り替えるようになっている。〔規格票7.2.2〕
- (6) 7ビットコード
-
Beginners' Macの連載記事PC Breakでは話を単純にするために日本語は8+8=16ビットで表すと書いたが、JISコード(ISO-2022-JP)は7+7=14ビットで構成されている。ASCIIなどが7ビットを標準にし、電子メールでは8ビット文字が使えない場合が多いことなどから、国際的規格(ISO)では7ビットを1バイトとして文字を表現する方法を定めており、JISにおいてもこの方式で文字セットを規定した。7ビット(128通り)のうち、実際に文字コードに使われるのは制御コードを除いた94文字だけなので、直接表現できる文字数は94 x 94 = 8,836となる。Unicodeでは16ビット空間をフルに利用して65,536文字を割り当てられるようになっている(もっともこれで世界中の文字がカバーできるわけではない)。
- (7) JISとエスケープシーケンス
-
インターネットで電子メールを受け取った時に文字化けして読めない原因として、どこかでこの [ESC] が脱落してモードの切り替えができないということがしばしば見られる。そういうときは$Bとか(Jというキャラクタが目につくはずだ。 たとえば
(例)これはJISの文です。
というJISによる文字列から何らかの原因で [ESC] が脱落すると
(例).$B$3$l$O.(JJIS.$B$NJ8$G$9!#.(J
のような暗号に化ける。 (この.の位置に
[ESC]があった。 ただし実際には.のような痕跡は残らないこともある) - (8) 半角カナ
-
JIS規格は文字セットとその符号化を定めるだけで、文字の形や大きさを定義するものではない。1バイトの仮名文字を2バイト文字の半分の横幅で表示するコンピュータが多いため、1バイト仮名を半角カナと呼ぶことがあるが、誤解を招く表現として指摘されている。