

HTMLの基本構造 - 仕様書に見るHTML(1)
1 仕様書を読んでみよう
1.1 仕様書は誰でも読める
HTMLを解説する記事や書籍はたくさんありますが、もっとも基本となるのは「仕様書」です。HTMLがどのような仕組みで構成され、どのように記述すべきなのかといった定義は、すべてこの仕様書に記載されています。
現在広く使われているHTML4.01(以下HTML4)の場合、仕様書はW3C のウェブサイトで公開されており、だれでも自由に読むことができます。この仕様書は、単なる言語の定義だけでなく、背景の説明や使用例、注意事項なども含んだ詳細なものです。PDF版を印刷すると400ページ以上にもなる膨大なものなので、通読するのは楽ではありません。しかし逆に、それだけ丁寧に書かれているので、きちんと読めば内容は十分理解することができ、正確なHTMLを身につけることができます。
このシリーズでは、HTMLに関して曖昧になりがちな部分が、仕様書ではどのように定義されているかを確認しながら、HTMLの理解を深めていきます。仕様書に馴染むことで、記事で取り上げない点についても、自分で調べてみようと思っていただければと考えています。
1.2 情報共有のための標準仕様
WWWは、さまざまな環境でネットワークに接続している人々が、コンピュータの機種やソフトウェアの違いに関係なく情報を共有できるように設計されました。より効果的な情報共有のためには、思い思いの方法で文書を記述するのではなく、共通の約束に基づいて書かれていることが重要です。
HTMLはWWWでの情報共有のための標準言語であり、その言語を誰もが正確に記述・理解できるように定義するのがHTMLの仕様書です。HTMLにはいくつかのバージョンがありますが、バージョン3.2以降はW3Cによって仕様が定められ、勧告されています。
1.3 W3Cの標準化作業
W3Cの定める標準技術文書は、W3C内外の議論を経て、最終的に「勧告」という形で公開されます。この勧告に至る流れを紹介して、W3C標準の位置づけを確認しておくことにしましょう。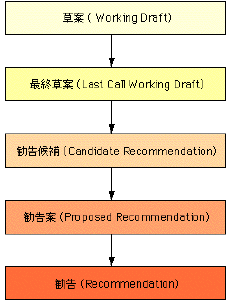
W3Cの標準化プロセスは、作業部会によって提出される草案(Working Draft)からスタートします。草案段階の討議がまとまると最終草案(Last Call Working Draft)が提案され、さらにこれが必要な要件を満たすと、勧告候補(Candidate Recommendation)としてメーカーによる実装検証などのテスト段階に入ります。この実績が十分なレベルに達すると、文書は勧告案(Proposed Recommendation)としてメンバー組織の諮問委員会に提出されます。この過程を経て、各方面の支持と合意を得るに至った規格がW3Cの勧告(Recommendation)です。
これらの各段階の文書はW3Cのサイトで公開され、我々のような一般ユーザもメーリングリストなどで意見を述べることができるようになっています。また、いずれかの段階で必要な要件を満たしていないと判断されると、規格は前の段階に差し戻されて再検討されることになります。HTML4.0は1997年7月に草案が公開され、11月に勧告案、12月18日に勧告と、かなりのスピードで標準化作業が進められました。
Recommendationの名が示すように、W3C勧告は強制力を持つ国際標準ではありません。しかし、この勧告は広く業界やユーザーから支持されており、事実上の標準規格と考えられます。
2 HTML4仕様書の構成と考え方
2.1 仕様書の目次を開いてみる
では、W3Cのサイトを訪れて、HTML4の仕様書を開いてみましょう。この仕様書は24の章と2つの付録から成っています。最初の3章が導入、続く21章がHTMLの言語仕様の定義と解説、そして付録では前バージョンからの変更点や、表示を最適化するための注意点などが記されています。
言語仕様の部分は、最初にHTMLの基本的な枠組みを示した上で、要素タイプを「構造」「プレゼンテーション」「インタラクティビティ」の3つのカテゴリーに分けて定義していき、最後にSGMLとしてのフォーマルな定義を行います。構造に関連する要素タイプは7〜13章、プレゼンテーションに関するものが14〜16章、インタラクティビティが17〜19章で定義されています。
2.2 仕様書にみる「よいHTML」
仕様書で要素タイプが3つのカテゴリーに分けられているのは、「よいHTML」の考え方を示すためでもあります。
Although it is not easy to divide HTML constructs perfectly into these three categories, the model reflects the HTML Working Group's experience that separating a document's structure from its presentation produces more effective and maintainable documents. (1.1)
仕様書の著者たちは、構造とプレゼンテーションを分離することが「より効果的でメンテナンスしやすい」文書につながると述べています。よいHTMLは、相互運用性(共有性)を高めるだけでなく、作者にとってもメリットがあるのです。
3 仕様書を読むためのDTD入門
3.1 仕様書とDTD
HTMLの文法規則は、文書型定義(DTD)という形で記述されます。言語仕様の各章でも、要素タイプの説明の冒頭でこのDTDによる定義が引用されて、それぞれの用法を示しています。
7.5.5 Headings: The H1, H2, H3, H4, H5, H6 elements
<!ENTITY % heading "H1|H2|H3|H4|H5|H6">
<!--
There are six levels of headings from H1 (the most important)
to H6 (the least important).
-->
<!ELEMENT (%heading;) - - (%inline;)* -- heading -->
<!ATTLIST (%heading;)
%attrs; -- %coreattrs, %i18n, %events --
>
仕様書では、"3.3 How to read the HTML DTD"でこのDTDの読み方も簡単に説明してくれていますので、ここに一通り目を通しておくと、要素タイプの使い方をすばやく、かつ正確に理解することが可能になります。
3.2 要素タイプ宣言
HTMLの要素タイプを定義する「要素タイプ宣言」では、タグの省略の可否と、要素内に出現する子要素のタイプと順序(内容モデル)を定義します。たとえばul要素タイプの定義は、
<!ELEMENT UL - - (LI)+ >
となっています。これは
- 開始タグ、終了タグともに省略不可
- 内容モデルとしては、
li要素を1つ以上もつ
ということを意味する宣言です。
要素タイプ名ULのあとに続く2つの「-」は、それぞれ開始タグと終了タグの省略不可を示します。ここが「O」となっていると、そのタグは省略可であることを意味します。つまり「- O」なら終了タグのみ省略可ということです。
内容モデルでは、要素内に出現してよい要素タイプを列挙します。内容の出現順序、回数は、表1のような記号で示されます。これらを組み合わせることで、ある要素の中にどんな要素をどんなふうに記述できるかが厳密に定義されるわけです。
| 内容モデル | 意味 |
|---|---|
| A | 要素Aが1回だけ現れる |
| A+ | 要素Aが1回以上出現する |
| A? | 要素Aが現れないか、1回出現 |
| A* | 要素Aが現れないか、任意回数出現 |
| +(A) | 要素Aはその子孫で出現して良い |
| -(A) | 要素Aは出現してはいけない |
| A | B | 要素Aもしくは要素Bのいずれか一方 |
| A, B | 要素A及びBがこの順序で出現 |
| A & B | 要素A及びBが任意の順序で出現 |
3.3 属性リスト宣言と実体宣言
また、DTDでは要素タイプがどんな属性を持つのかも定義します。属性は、<!ATTLIST で始まる宣言文で、属性名、属性値のタイプ、省略時の扱いについて定義します。
さらにDTDでは、さまざまな名前や値の別名を定義しておき、個々の宣言ではこの別名を使うのが普通です。この別名の定義を実体宣言といい、<!ENTITY で始まる宣言で定義しています。
仕様書の3.3ではこれらについても詳しく説明されています。それほど複雑ではないので、できればひととおり目を通して、DTDの読み方を身につけておきましょう。
4 HTML文書の構造
では、HTML4の仕様書のさまざまな要素タイプの定義の中から、注目しておきたい部分を拾い読みしていきます。HTMLを書くときに、「ここはどうなっているんだろう」と疑問に思うような点の多くは、実は仕様書できちんと解説されているものなのです。まず第7章を開いて、HTML文書の基本構造を示す要素タイプを見てみます。
4.1 title要素タイプとtitle属性
title要素はHTML文書が最低限持たなければならない重要な要素です。しかしこの要素は、ブラウザのウインドウタイトルに示されるだけであまり目立たないので、その役割が意外に理解されていないのも事実。仕様書の説明を読んでみましょう。
Authors should use the TITLE element to identify the contents of a document. Since users often consult documents out of context, authors should provide context-rich titles. Thus, instead of a title such as "Introduction", which doesn't provide much contextual background, authors should supply a title such as "Introduction to Medieval Bee-Keeping" instead. (7.4.2)
「読者は多くの場合、文脈を離れたところで文書について調べるので、作者は文脈をも伝えるタイトルを用意すべき」というのは、タイトルを考えるに当たっての基本です。「文脈を離れたところ」とは、検索エンジンの結果リストに一覧表示される場合を考えてみるとわかるでしょう。単に「Introduction」だけでは意味が通じませんね。

文書の内容を示すのがtitle要素なら、個々の要素について具体的に説明するのがtitle属性です。
Values of the title attribute may be rendered by user agents in a variety of ways. For instance, visual browsers frequently display the title as a "tool tip" (a short message that appears when the pointing device pauses over an object). Audio user agents may speak the title information in a similar context. (7.4.3)
実際、新しいブラウザでは、title属性を持つ要素の上にマウスを持っていくと、ツールチップやステータスバーにその内容が表示されます。本文では詳しく説明しきれないようなヒントを、ツールチップなどで提供するのは、スマートで読者にとっても親切な方法です。

4.2 meta要素タイプと言語情報
文書のメタ情報、つまり文書自身に関する情報は、meta要素タイプを使って示します。一般には情報の種類(プロパティ)をname属性で、その値をcontent属性で記述します。例えば
<meta name="keywords" content="corporate,guidelines,cataloging">
と指定することで、検索エンジンのロボットなどに、文書に含まれるキーワードを教えることが可能です。
name属性の代わりにhttp-equiv属性を用いると、サーバーが送り出すメタ情報である「HTTPヘッダ」に相当する情報を示すことができます。たとえば、文書の文字コードは本来サーバーで指定すべきものですが、一般利用者がサーバー情報を設定できるとは限りません。このような場合、文書にmeta要素を加えることでその文字コードを明示できます。
<meta http-equiv="Content-Type" content="text/html; charset=Shift_JIS">
meta要素はhead要素内のどこに記述しても構いませんが、title要素で日本語を使う場合は、それ以前にHTTPヘッダもしくはmeta要素で文字コードを指定しなければなりません。
The META declaration must only be used when the character encoding is organized such that ASCII-valued bytes stand for ASCII characters (at least until the META element is parsed). META declarations should appear as early as possible in the HEAD element. (5.2.2)
meta要素を用いて、自動的にページを移動する機能を提供するブラウザがあります。しかし、この方法はアクセシビリティを損なうため、使わないよう警鐘が鳴らされています。
Some user agents support the use of META to refresh the current page after a specified number of seconds, with the option of replacing it by a different URI. Authors should not use this technique to forward users to different pages, as this makes the page inaccessible to some users. Instead, automatic page forwarding should be done using server-side redirects.
アクセシビリティの高いページづくりは、HTML4の仕様書が目指す重要な目標の一つなのです。
4.3 headings(見出し)
本文を記述する上で大切なのは、適切な見出しを用意して文章の構造を理解しやすくすることです。
A heading element briefly describes the topic of the section it introduces. Heading information may be used by user agents, for example, to construct a table of contents for a document automatically. (7.5.5)
見出しを提供するのは、人間の読者にそのセクションのトピックを簡潔に示すとともに、コンピュータの力を使った情報共有の面からも重要であることが示されています。目次の自動生成などを考えると、見出しの本質は「文字の大さ」ではなく、大見出し、中見出し、小見出しといった階層によるトピックのレベルの明示であることがよく分かるでしょう。
仕様書では
Some people consider skipping heading levels to be bad practice. They accept H1 H2 H1 while they do not accept H1 H3 H1 since the heading level H2 is skipped.
と控えめに書かれていますが、見出しレベルの順序が不適切では、目次はうまく生成できませんね。より厳格な規格であるISO-HTMLでは、この順序についても仕様できちんと定められています。
4.4 id,class属性とdiv,span要素タイプ
HTMLでは限られた要素タイプしか定義していないので、きめ細かな構造表現のためにはid、class属性やdiv、span要素タイプを利用します。idとclassの違いがよく分かりませんか? 仕様書には、次のような説明があります。
The id attribute assigns a unique identifier to an element ... The class attribute, on the other hand, assigns one or more class names to an element; the element may be said to belong to these classes. A class name may be shared by several element instances. (7.5.2)
idはある要素を文書の中で唯一のものとして識別するためのID、classはHTML要素タイプにはない新たな分類を示すための名前という役割を持つわけです。ある要素は、複数のクラスに属することもできます。その場合は、クラス名を空白で区切って列挙します。
<p class="note exception">【注】ひとつ例外がある...</p>
idやclassは、HTMLの要素タイプをもとにして、より細分化した構造記述を可能にします。既存の要素タイプではカバーしきれないグループを構造的に示すためには、これらの属性をdiv, span要素と組み合わせます。こうした構造は、スタイルシートを使って視覚的に表現することが可能です。
The DIV and SPAN elements, in conjunction with the id and class attributes, offer a generic mechanism for adding structure to documents. These elements define content to be inline (SPAN) or block-level (DIV) but impose no other presentational idioms on the content. Thus, authors may use these elements in conjunction with style sheets, the lang attribute, etc., to tailor HTML to their own needs and tastes. (7.5.4)
仕様書では、div要素タイプを使って章、節を表現する例が挙げられています。
<DIV class="section" id="forest-elephants" > <H1>Forest elephants</H1> <P>In this section, we discuss the lesser known forest elephants. ...this section continues... <DIV class="subsection" id="forest-habitat" > <H2>Habitat</H2> <P>Forest elephants do not live in trees but among them. ...this subsection continues... </DIV> </DIV>
5 テキストをマークアップする
仕様書の第9章は"Text - Paragraphs, Lines, and Phrases"と題されていて、本文を構成する段落とその内部のフレーズのマークアップ、引用および空白文字や行の扱いについて定義しています。
5.1 パラグラフと行
文章の基本であるパラグラフ(段落)を示すのはp要素タイプです。パラグラフとは見かけ上の改行のことではなく、ひとつのトピックを扱う文のまとまりを指します。仕様書ではこのパラグラフの考え方も簡潔に説明してくれます。
Authors traditionally divide their thoughts and arguments into sequences of paragraphs. The organization of information into paragraphs is not affected by how the paragraphs are presented: paragraphs that are double-justified contain the same thoughts as those that are left-justified. (9.3)
多くのブラウザはパラグラフの間に1行の空行を挿入しますが、これはHTMLの仕様で定められているわけではなく、歴史的経緯でそういうスタイルが一般化しているだけであることに注意してください。
HTML user agents have traditionally rendered paragraphs with white space before and after...This contrasts with the style used in novels which indents the first line of the paragraph and uses the regular line spacing... Style sheets provide rich control over the size and style of a font, the margins, space before and after a paragraph, the first line indent, justification and many other details. (9.3.5)
スタイルシートを用いれば、普通の書籍のように、段落の間には空白を置かず、1字下げによって段落を示すことも可能になります。
5.2 改行と空白文字
HTML文書では、改行やスペースなどの空白文字は、pre要素以外では無視されることはよくご存知の通りです。しかしこの「無視される」というのは、厳密にはどういうことでしょうか。
For all HTML elements except PRE, sequences of white space separate "words" (we use the term "word" here to mean "sequences of non-white space characters"). (9.1)
連続する空白文字は「単語の境界」を示すと定義されています。ブラウザには、この単語境界を言語(script)や出力メディアに応じて適切に表現しなければなりません。
For example, in Latin scripts, inter-word space is typically rendered as an ASCII space ( ), while in Thai it is a zero-width word separator (​). In Japanese and Chinese, inter-word space is not typically rendered at all. (9.1)
画像をリンクのアンカーとするときに、imgタグとaタグの間に改行を入れると古いブラウザでは「ヒゲ」が付いてしまうことがあります(画面8)。これは、ブラウザが改行を欧米言語の単語境界と考え、スペースを挿入したところにアンカーを意味する下線が表示されたわけですね。
5.3 qとblockquote
作者の考えと他の文献からの引用を区別することは極めて重要なので、HTMLではq要素タイプで文中の「引用句」を、blockquote要素タイプでひとまとまりの「ブロック引用」を明示します。
q要素はその内容が引用句であることを意味するので、ブラウザはその部分を引用符で囲んで表示すべしということが仕様書に書かれています。
Visual user agents must ensure that the content of the Q element is rendered with delimiting quotation marks. Authors should not put quotation marks at the beginning and end of the content of a Q element. (9.2.2)
しかし、ブラウザの対応がまちまちであるため、この規定は難しい問題をはらんでいます。仕様書に従って""や「」の表示をブラウザに任せると、古いブラウザでは引用句が区別できません。逆に、q要素にテキストでこれらの記号を加えると、新しいブラウザでは引用符が重複して表示されてしまいます。q要素は、仕様とブラウザの実装のギャップが大きい例の一つです。
一方ブロック引用は、「」を用いたり字下げで示したりと、作者によって表現方法はさまざまでしょう。仕様書でも、blockquote要素については、スタイルシートで適切な引用符が付与できるようにすべしと推奨するにとどめています。
このblockquoteを単なるインデントのために使うという悪しき習慣は、まだ一部で残っているかもしれません。そのため、仕様書の記述は歯切れの悪いものになってしまいました。
However, as some authors have used BLOCKQUOTE merely as a mechanism to indent text, in order to preserve the intention of the authors, user agents should not insert quotation marks in the default style. The usage of BLOCKQUOTE to indent text is deprecated in favor of style sheets. (9.2.2 Note)
不正確なタグ(要素タイプ)の用法は、このように本来の機能を阻害してしまうことがあります。ウェブの未来のためにも、仕様書をきちんと理解し、正しいHTMLを書くよう心がけましょう。