
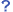

ハイパーカードでウェッブ!
インターネットが一般にも認知されワールド・ワイド・ウェッブ(WWW)が普及してきた。ハイパーカードを駆使してこの波に乗ってしまおう。
情報共有とWWW
WWWとともにインターネットが急速に裾野を広げている。グラフィックを使った表現と、ハイパーリンクによる小気味よいナビゲーションは、新しい時代の情報ツールと呼ぶにふさわしいものだ。ところで、既に利用している人はよくご存知の通り、このWWWブラウザというアプリケーションは、インターネット上の資源に限らずローカルディス上のファイルでも、同じように働く(*注1)。これを利用すると、例えばマニュアルや社内連絡をグラフィック付きのハイパーテキストで提供することができる。しかも、この形式ならマッキントッシュに限らず、Windowsでもそのまま同じ情報を表示できるというおまけつきだ。
問題は、いかにして情報をHTML(*注2)で提供するかというところである。ハイパーカードの場合は、仕組みづくりにスクリプティングなどの準備が必要だが、情報自体はほとんど単純なテキストで良かった。逆にWWWでは、高度な表示機能をブラウザが持っている代わりに、提供側がリンクなどの仕掛けを情報の中に埋め込まなければならないのである。
毎日生み出される情報をいちいちHTMLに書き直しているのでは手間がかかって仕方がない。かといって時間があるときにまとめてなどと考えていると、情報はどんどん古くなるし、忙しさの中で立ち消えになる恐れもある。
しかし、HTMLといえども所詮はテキストファイル。ハイパーカードでうまく処理することが可能なのではないか。
HTMLとタグ
(注)この記事の説明は、HTMLの理解のためには適切ではありませんのでご注意ください。
HTMLは、普通のテキストの中にタグと呼ばれる記号を埋め込むことで、文書の形を整えたり、他のファイルにジャンプしたりできるようにしたものである。例えばある部分をイタリック体にしたければ
<i>イタリックにする部分</i>
とするだけだ。理屈は簡単だが、これをエディタ上で一つづつ書き込んでいくのはいかにも効率が悪い。テキストを選択し、ボタンを押せば自動的にタグが埋め込まれるという機能が欲しいところだ。
前回までの連載で示したように、こういう文字列処理は、ハイパーカードの得意とするところである。世の中には、HTMLエディタと呼ばれるものがいくつも出回っているが、組織的に情報をHTML化するには、自分たちの情報形態に応じてカスタマイズできるものが必要だ。文字列処理の応用編として、スタック版HTMLエディタを作ることにしよう。
ハイパーカードでのタグ付け
スタックによるHTMLエディタの基本は、マウスで選択(セレクト)したフィールドのテキストに対して、ボタンでタグ付けの命令を出せるような仕組みである。
選択部分の情報はthe selectedChunkという関数を使ってchar XX to YY of bkgnd field 1のように取得できる。この部分をイタリック体にするにはリスト1のようにすればよい。選択部分のポジションを調べ(1)、その内容を取り出し(2)、前後にタグをつけ加えてもういちど同じところに書き込む(3)という操作だ。ほかのタグを挿入する場合も、BindMeの引数を変えるだけで済む。
ハイパーリンクも、このタグ付けの簡単な応用である。リスト2を見てみよう。最初の部分はリスト1のBindMeと同じ。answer fileでリンクするファイルを選び、<a href="file name">のようにタグを付け(*注3)、もとの場所に書き込む。これだけの操作で、選択部分がWWW上でアンカー(*注4)となり、クリックするとFileNameで指定されたファイルが呼び出される。
画像の取り込みも基本的に違いはない。タグの書式が異なるので、リスト2の(2)の部分が(3)のようになるだけである。
簡単版エディタスタック
これだけの材料でも充分HTMLエディタができるので早速試してみよう。スタックは、テキスト編集用のフィールドのほか、タグ付けやファイル・画像リンクのためのボタン数種類を加えただけのものだ。バックグラウンドにリスト1のBindMeハンドラを置き、左の3つのボタンからこれを呼び出す。右の2つのボタンにはそれぞれリスト2のスクリプトを用意する。画面1-1のようになる。以上である(*注5)。
フィールドに適当なテキストを用意し、文字列をセレクトしてどれかボタンをクリックしてみよう。直ちにタグが挿入されるはずだ。画像ファイルを用意して「Image」をクリックすると、ちゃんと<img src=...>というタグも加わった。このようにしてタグ付けした画面1-2のテキストをWWWブラウザで表示してみると、画面1-3のようになる。申し訳ないほど単純な仕組みで、いちおうWWWのようなものができあがってしまった。
HyperDBとの連動
ここまではごく普通のHTMLエディタを真似してみたに過ぎない。本企画のコンセプトどおりテキストデータを徹底活用するために、次に7月号のHyperDBのファイル(以下HDB)(*注6)をHTML形式に変換する機能を考えてみよう。
WWWでは、冒頭にタイトルの一覧が示され、クリックすると本文にジャンプするようになっているものが多い。WWWでの情報閲覧はリンクが頼りなので、こうしたリストを最初に用意するのは大切なことである。HDBのように、タイトルと本文という構造が明確なテキストは、比較的簡単にリンクリストを作成することができる。
HTMLのリストは図1のように表現するが、目次のときは<li>のうしろにリンク先を示すタグ<a href="#myname">...を加える(*注7)。リンク先には参照名を示すタグ<a name="myname">...を用意しておく。ではHDBを読み込んでこれらのタグを割り当てていくことにしよう。
HyperDBのファイルの自動変換
 リスト3は、HDBのデータstrを処理する関数だ。今回のハイライトなので詳しく解説する。
リスト3は、HDBのデータstrを処理する関数だ。今回のハイライトなので詳しく解説する。
まず(1)で変数の初期化を行う。sepはHDBのレコード区切り行である。statusは、処理している行が見出しか、本文かなどを区別するためのフラグ。値が1なら、次の行が見出しであることを示している。LinkIDは、処理中のレコードが何番目のものかを示す。
(2)以下が実際のデータ処理の部分である。strを1行ずつ調べ、statusのフラグに従って分岐を行う。
処理する行が区切り行の場合(3)はstatusを1にセットし、次に来る行が見出し行であることを宣言する。そして(4)以下で見出しのリンク付けを行うわけだ。
まず参照名を変数LinkNameにセットし(5)、これを使ってリンクリストを作成する(6)。<a href=...>でアンカーをつくり、リスト形式とするために行頭に<li>タグを加えているのである。
(7)で参照先の見出しを作成する。行頭に<dt>というタグを加えて辞書スタイルの表示ができるようにした。見出し処理が終わったらLinkIDを一つ繰り上げる。
(8)以下では本文の処理を行うが、見出しの次の行のみ行頭に<dd>というタグを加える。辞書スタイルのリストで、ここからが本文であることを示すためだ。[*ここは不正確なので注を参照]
全ての行の処理が終わったら、(9)で一覧には<ul>、本文には<dl>タグをつけ加え、適切なリスト表示ができるように設定した上で結果を返す。
このスクリプトを使って今回の原稿をHTML化したのが画面2である。WWWで表示すると、画面3のようになった。
定型文書処理への応用
前項のHDBデータの処理の基本は、
- ある規則に従ったデータを読み込み
- 各行についてそれが見出しか本文かを判断し
- 見出し部分に参照用のタグを加え、同時にリンクリストとしても抽出する
という流れであった。ポイントは、どうやって見出し行を判断するかということである。これさえ押さえれば、様々な箇条書きタイプのオフィス文書を、同じ手法でHTMLに自動変換できるはずだ。
例えば、1,2,3...と半角数字で見出しを付けた箇条書き文書の処理を考えると、
put 1 into SectionID
repeat
if word 1 of theLine is SectionID then
(見出しの処理)
add 1 to SectionID
else
...
のような形で見出しを見分けることができる。
こうした自動変換を応用すれば、規則的な書式の規定集などを一括してHTMLに変換することも難しくない。WWWによるハイパーマニュアルも、意外にすんなりと実現可能なのではないだろうか。
サンプルスタック(HyperHTEdit)には、ハイパートークで実現可能な範囲で様々な編集用スクリプトを用意した。これらを参考に、自分のニーズにあったエディタを工夫し、オフィス文書のHTML化に挑戦してみて欲しい。
注
*注1
この場合はTCPなどの設定も必要ないので、ファイルさえあればすぐに社内WWWを始めることができる。
*注2
HyperText Markup Language。WWWで表示するためのドキュメントを作成する書式で、通常のテキストに文章の論理構造を示す「タグ」といわれるマークを加えたもの。HTMLについて及び基本的なタグ参照
*注3
他のフォルダにあるファイルを参照する場合も同じだが、WWWではパスを区切るのに":"ではなくUNIX風に"/"を使うので、これを置き換える必要がある。
*注4
リンクを行うタグのことをアンカー(錨)と呼ぶ。<a ...>というタグはAnchorの意味である。
*注5
ボタンのオートハイライトをオフにすることに注意。こうしておかないと、ボタンをクリックした瞬間にテキストフィールドの選択が解除されてしまい、the selectedChunkを使って目的の文字列を取得できなくなってしまう。
*注6
レコードをハイフン2つの行(--)で区切り、各レコードの最初の1行を見出しとするテキストファイル(1995/7号:データファイルの作成参照)。
*注7
リンク先が文書内の特定の場所になるときは、参照名の前に#を付ける。別のファイルなら<a href="filename#myname">となる。
リスト
リスト1
on mouseUp BindMe "<i>" -- イタリックのタグを設定する場合 end mouseUp on BindMe Tag get the selectedChunk --(1) put word 2 of it into p1 put word 4 of it into p2 get char p1 to p2 of fld 1 --(2) put Tag into EndTag put "/" after char 1 of EndTag put Tag & it & EndTag into char p1 to p2 of fld 1 --(3) end BindMe
リスト2
get the selectedChunk
put word 2 of it into p1
put word 4 of it into p2
answer file "リンクするファイルを選んで下さい"
put lastHCItem(":", it) into FileName --lastHCItemは解説参照
get char p1 to p2 of fld 1 --(1)
put "<a href=" & quote & filename & quote & ">" & it & "</a>" into char p1 to p2 of fld 1 --(2)PUT X into Yの解説参照
--インライン画像の場合は(1)を省略し、(2)を次のように書き換える
put "<img src=" & quote & filename & quote & ">" before char p1 of fld 1 --(3)
リスト3
function readHDB str
--(1)
put "--" into sep
put 1 into status
put 1 into LinkID
put QUOTE into Q
put RETURN into CR
put "" into Titles
put "" into bodyStr
--(2)
repeat with i= 1 to number of lines of str
set cursor to busy
get line i of str
if it is sep then --(3)
put 1 into status
else if status is 1 then --(4)
put "P" & LinkID into LinkName --(5)
put "<li><a href=" & q & "#" & linkname & q & ">" & it & "</a>" & CR after Titles --(6)
put "<dt><a name=" & q & linkname & q & "><b>" & it & "</b></a>" & "<br>" & CR after bodyStr --(7)
put 2 into status
add 1 to LinkID
--(8)
else if status is 2 then
put "<dd>" & it & "<br>" & RETURN after bodyStr
put 0 into status
else
put it & "<br>" & RETURN after bodyStr
end if
end repeat
--(9)
put "<dl>" & CR & bodyStr & CR & "</dl>" into bodyStr
return "<ul>" & CR & Titles & "</ul>" & CR & "<hr>" & CR & bodyStr
end readHDB
用語
- PUT X into Y
-
Xの内容をBに代入するという最も基本的な命令ですが、これをput X into char 3 to 4 of Yとした場合、Xが2文字以上あるとどうなるでしょう。例えば
put "12345678" into Y put "abcd" into char 3 to 4 of Y
とすると、Yは12abcd78と上書きされずに12abcd5678と割り込まれた形になります。この仕組みがあるために、リスト1の(2),(3)のように、char p1 to p2として取得した文字列にタグを加え、もう一度char p1 to p2に書き込むということが可能になるのです。
また、put "/" after char 1 of Y とするとYは1/2345678となります。これを利用して、タグ<b>から終了のタグ</b>を作ります。
- lastHCItem
-
これはHomeスタックに用意されているユーティリティ関数です。文字列strがcという文字でいくつかの部分に区切られているとき、lastHCItem(c,str)とするとその最後の部分が返されます。例えばlastHCItem(":", "HD:MacUser:MyFile")とするとパス名からファイル名MyFileだけを取り出すことができるのです。
- オートハイライト
-
ボタンの属性の一つで、クリックしたときにmouseDownでハイライト(黒)になり、mouseUpで通常に戻るという設定です。基本的にハイパーカードでは、フィールドの選択部分も含めて同時にハイライトされる部分は1カ所だけなので、ボタンをクリックしたときにオートハイライトがセットされていると、フィールドの選択が解除されてしまいます。
HyperText Markup Language
HTMLについて
HTML(HyperText Markup Language)とは、WWWブラウザでハイパーテキストの表示をするために、普通のテキスト文書にマークアップタグ(markup tags)という記号を加えた表現形式です。これは本来は見出しや段落といった「文書の論理構造」を記述するための方法で、実際の表現(フォントやレイアウトの選択)はブラウザに任されています。したがって、機種やブラウザを問わずに同じデータを表現できる代わりに、ブラウザごとに少しずつ見え方が違う可能性があります。
基本的なタグ
【お詫びと訂正】
この原稿を書いた当時、まだHTMLをきちんと理解していたとは言いがたい部分があります。
この「基本的なタグ」セクションで紹介した内容は、説明が不十分で誤解を招く恐れがあるので、削除します。当サイトのごく簡単なHTMLの説明をご覧ください。
また、本文中でも、見出しを<dt>で示し、本文を<dd>にするというくだりは、辞書型リスト本来の使い方とは違っています。ここではやはり<hn>を使って見出しを示すべきでしょう(96.11.03)。
(MacUser Japan, September 1995)