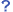

ウェブのデータと検索の可能性
- 検索の手順:何をコンピュータに任せられるか
- 文書の検索と情報の検索
- 文書のウェブからデータのウェブへ
- エージェントが扱える(メタ)データ表現
- URIを用いたグローバルな識別
- データ属性と語彙の共有
- SPARQLクエリ言語
- SPARQLのプロトコルと結果フォーマット
- データはどこにあるのか
- XHTMLを活用した文書内データの精度の向上
- XSLTによる(メタ)データの抽出
- GRDDL:汎用的な抽出
- SPARQLの検索とプレゼンテーション
- 人間による試行錯誤からエージェントの推論へ
- 参照先
(※当日のデモは割愛します)
文書の検索と情報の検索
- 情報を知るためには
- 情報が記述されている文書(書籍、ウェブページ)を検索して内容を読む
- 情報を(あらかじめ整備されたデータベースなどで)直接調べる
- 文書の中の情報が検索できたら? 人間に代わってコンピュータが文書内から情報を取り出してくれたら?
- 2006年5月のユニバーサロン・セミナーで何が行われるか調べるために
- キーワードでユニバーサロンのページを検索し、セミナー情報を読む
- イベント情報データベースを検索する
- ユニバーサロンのページに記述された情報を「カレンダー情報」として抽出して検索する
エージェントが扱える(メタ)データ表現
- データの属性と値
- 属性:何を表すデータか(プロパティ)=開催日
- 値:データの内容=2006-05-11
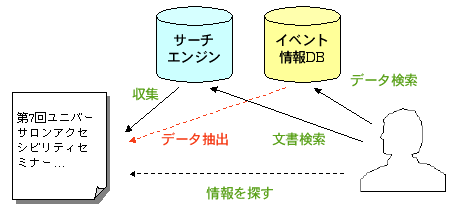
- RDFによる汎用的なデータ表現
- 主語+述語(プロパティ)+目的語(値)
- このイベントの開催日は2006-05-11だ。

- 文書に含まれるデータの表現
- この文書のトピックはこのイベントだ。このイベントの開催日は2006-05-11だ。
URIを用いたグローバルな識別
- データの的確な処理には曖昧さのない識別が重要
- 一般的なエージェントは文脈による判断ができない
- 特定コミュニティの了解事項はグローバルには通用しない
- 対象をURIで識別
- 「このイベント」は文脈を共有しなければ通じない
- http://www.mainichi.co.jp/universalon/events/20060511
- データ属性の共通化
- 文書に記述された情報は「開催日」「日付」「date」などまちまち
- http://purl.org/dc/elements/1.1/date というURIで曖昧さなくプロパティを表す
- 人間が扱うには dc:date のような形で接頭辞を用いた短縮表記

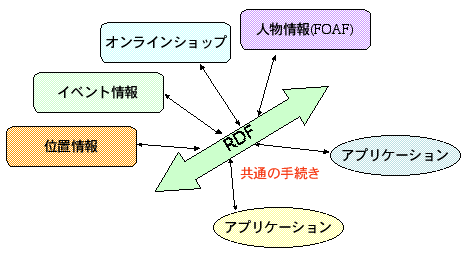
データ属性と語彙の共有
- 個別サービスの検索
- ウェブ文書の詳細検索(日付、ドメイン、ファイルタイプetc.)
- OPAC、オンラインショップ、ウェブサービスetc.
- 対象属性、検索手続きは一般にサービス固有
- データの共通バスとしてのRDF
- URIで識別されるグローバルな語彙を用いる
- 語彙のマッピングにより異なるサービスを横断したデータ検索が可能