
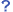

RDFとメタデータの相互運用
- (メタ)データ相互運用の課題
- データ相互運用とRDF/OWL
- 汎用語彙によるシンプルなRDFの記述
- 関係記述の詳細化
- クラスを利用した役割の定義
- …注意点(1):役割クラスと実体の識別
- …注意点(2):役割クラスを与える実体は併合に注意
- より掘り下げたモデル
- プロパティの粒度と部分の表現
- データの共有と交換
- 共有(1):同じ深さのモデルで独自語彙を用いる場合
- 共有(2):役割クラスを用いる場合
- 共有(3):モデルの深さが異なる場合
- 共有(4):部分関係に分割されたプロパティ
- 共有(5):語彙とモデルの変換
- データの交換
- RDFを利用したデータ交換
- データ交換とハブ
- 相互運用可能な語彙の考え方
- Appendix:詳細プロパティと役割クラスについて
- 参照先
汎用語彙によるシンプルなRDFの記述
- 汎用語彙による記述のメリット、デメリット
- 長所:広い分野で利用でき、相互運用性が高い;シンプルで分かりやすい;(比較的)安定している
- 短所:表現力が弱い;用法が不明瞭、不正確な場合がある(→相互運用の支障になる可能性)
- Dublin Core記述モデルのばらつき
- 目的語(著者)を単純にリテラル(名前文字列)で表現する

- 著者をエンティティ(人物)とし、そのプロパティとして名前を与える(より抽象モデルに忠実)
- 単純なクエリでは両者を同時に検索できない
- 過去の経緯で使い方が曖昧になっている
- DCMIは2005年に抽象モデルを定義、2007年には新たな抽象モデルとdcterms:名前空間による定義域、値域を定める案が出されている
- (※RDFグラフの図において、水色の円は空白ノード、緑の円はURIを持つノードを表します。以下のスライドでも同様です。)
関係記述の詳細化
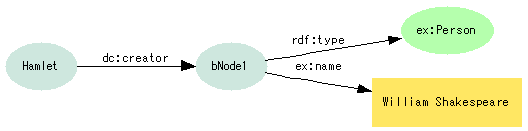
- 作者から著者と翻訳者へ
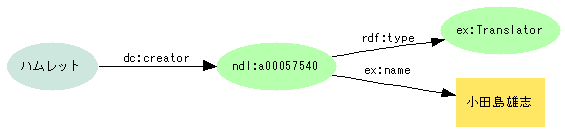
- William Shakespeare著, 小田島雄志訳『ハムレット』をどう記述するか
- Dublin Coreの基本要素だけでは、著者、訳者ともに
dc:creatorとなって区別ができない
- 詳細化のためのプロパティ定義とサブプロパティ
- 著者を表す
ex:author、翻訳者を表すex:translatorを定義 ex:authorとex:translatorをdc:creatorのサブプロパティとして関連付ける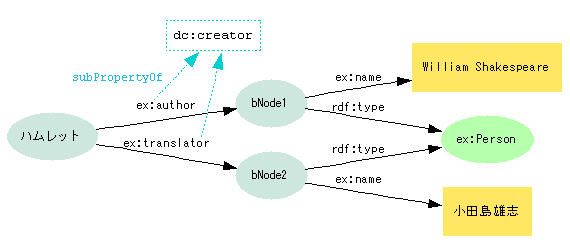
- 著者を表す
クラスを利用した役割の定義
- プロパティを増やさず役割クラスで明確化する方法
- ドメインのニーズを全て満たす詳細化プロパティの定義は複雑
- 汎用プロパティの目的語に型(ロールを表すクラス)を与えることで役割を識別できる
- 多くの役割クラスは汎用オントロジー(例えばWordNet/RDFなど)で定義されている可能性が高い
- 独自定義の必要性が低い=相互運用性が高い
- 著者、訳者をAuthor、Translatorクラスで表現
- 書籍のプロパティは
dc:creatorのままで、目的語エンティティ(人物)に役割クラスを与える - ここでの役割クラスは、MODSのrole属性の働きに近い
…注意点(1):役割クラスと実体の識別
- 役割クラスを持つ実体にURIを与えると
- 役割クラスを与えた人物に、例えば著者名典拠IDをURIとしてあたえて識別を図る?
- しかし、同じエンティティが常に同じ役割クラスを持つとは限らない(あるときは著者、あるときは翻訳者)
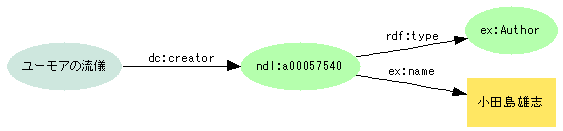
- このデータをレポジトリなどに集めて共有するとどうなるか
…注意点(2):役割クラスを与える実体は併合に注意
- URIを持つ実体を併合したときに、主語と役割の関係が分からなくなる
- 2つのグラフを併合すると、URIを与えた人物ノードは1つにまとめられ、役割クラスは機能しなくなる

- 空白ノードは併合されないので、URIを与えなければこの問題は生じない
- 役割クラスを持つ実体は
IFPで間接的に識別する- 著者名典拠IDを実体のURIにするのではなく、
dc:identifierなどを用いて間接的に識別する 
- 一般に、RDFで複数のトリプルの組み合わせで意味を表現するとき、ハブを空白ノードにしないと併合したときに混乱する恐れがあるので注意
- この場合の空白ノードは人物自身というよりも、SNS記述モデルでのユーザアカウントに近い、その人のある面(翻訳者、作家など)を切り取った存在と考えることができるでしょう。役割は人物実体身の属性ではなく、作品と人物の「関係の属性」なので、Schema.orgでのRoleモデルのような考え方も有効です。(2016-02-13追記)
- 著者名典拠IDを実体のURIにするのではなく、
より掘り下げたモデル
- FRBRのエンティティモデルによるRDFグラフ
- Hamletという作品(
Work)の日本語訳(Expression)の白水社版(Manifestation)という関係 - 作品の作者はShakespeare、日本語訳の作者は小田島雄志として表現できる
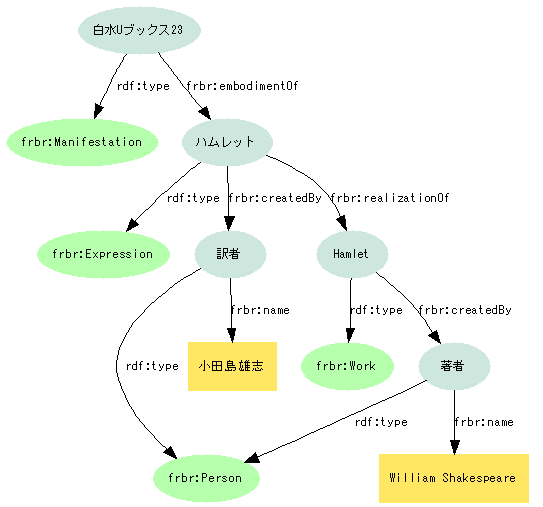
- Hamletという作品(
プロパティの粒度と部分の表現
- 1つのプロパティの関係が複数のプロパティに分割されることがある
- 「名前」を姓と名に分ける、「住所」を国、都道府県、市町村、番地に分ける、など

- モデルは、
(著者)--name-->(名前)--surname-->"Shakespeare".という間接的部分関係と考えられるが、直接関係として表現されることも多い。
- 共有・交換のボトルネックになりやすい
- 部分→全体の操作はできるが、全体→部分の操作は難しい
- 姓と名から氏名を作ることはできるが、氏名を姓と名に分割できるとは限らない
- RDFノードの結合(合成)は一般的な操作ではない
- 姓ノードと名ノードから氏名ノードを作るには、基本的なグラフ操作ではなく、処理系依存の文字列連結関数などが必要
- 部分→全体の操作はできるが、全体→部分の操作は難しい
共有(1):同じ深さのモデルで独自語彙を用いる場合
- サブプロパティ定義があれば推論可能
ex:author、ex:translatorのサブクラス定義からdc:creatorを推論できる(dc:creatorでもex:authorでも検索できる)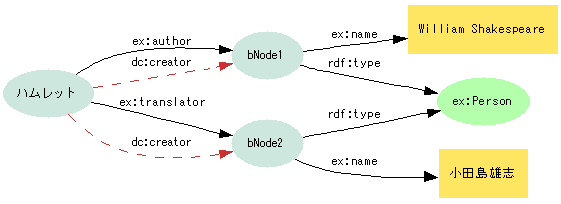
- 個別のデータ変換は不要
- RDFスキーマの基本推論(RDFS推論)で汎用プロパティのトリプルをグラフに加えることができる
- 元のプロパティも失われない(推論結果で置き換えるのではなく追加される)
- データ提供者は、スキーマを公開するだけでよく、自分でデータ変換する必要がない
共有(3):モデルの深さが異なる場合
- 独自の推論規則で汎用的なトリプルを追加
- FRBRモデルからDCプロパティを生成する推論規則を定める
{?book frbr:embodimentOf ?expr . ?expr frbr:realizationOf ?work . ?work frbr:createdBy ?author .}=>{?bookdc:creator?author .}- 推論エンジンを使ってdc:creatorのトリプルを加えることができる(例はcwmによる推論)
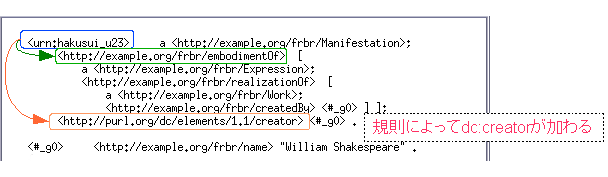
- 生成されたトリプルを利用して、前節と同様のSPARQLで検索ができる
- ただし、RDFS推論は主な処理ライブラリで提供されるが、こちらは独自の規則定義と推論エンジンが必要
RDFを利用したデータ交換
- 役割クラスを介する交換
- データを汎用属性+役割クラスとしてエクスポート(公開)する
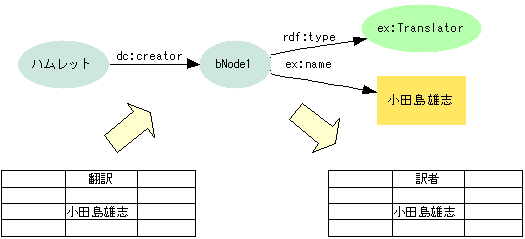
- 役割クラスに対応するフィールドがあれば、データを直接取り込むことができる
- 直接対応するフィールドがなければ、汎用プロパティ(dc:creator)に対応するフィールド(作者など)に取り込む
- 共通の詳細化プロパティを用いる交換
- 役割クラスよりも直接的に交換が可能
- 対応するフィールドがない場合はサブクラス定義を利用する
- 共通詳細化プロパティをどの程度定義し、普及させるかが課題
データ交換とハブ
- ハブとなるサービスを介した交換
- 直接交換は対象が増えると効率が悪い → 共通のレポジトリ(ハブ)を介しての交換
- ハブ段階で情報が失われる(簡略化される)と回復できない → ハブのモデル設計が重要
- ハブ側変換とソース側変換
- データハブが推論・変換を請け負う
- ソースの負担が軽く、多くの参加を得やすい
- データ公開(ソース)側がハブ向けに変換を行う
- データ共有のステップとしては確実だが、ソース側に変換技術が必要
- ソース側のモデルに応じたきめ細かな変換が必要な場合
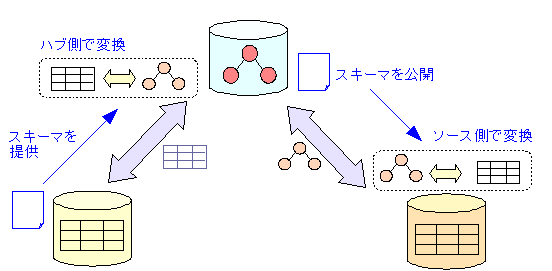
- データハブが推論・変換を請け負う