
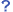

RDF再訪:設計、課題、そして応用
RDFのコア(1):トリプルとグラフ
- RDFはトリプルを集めたグラフ
- 自然文とおなじくRDF文も主語、述語、目的語(トリプル)で構成される
- RDFは主語と目的語のノードを述語で結ぶ有向ラベル付きグラフで表現される
- さまざまな形の情報を共通の単純構造に
- 表もトリプルの組み合わせ(=グラフ)で表現可能
- より複雑なネットワーク構造もグラフで表現できる
- 複雑な構造を単純なトリプルに分解し、また逆に元の構造を復元できる
RDFのコア(2):URIと共通=標準化
- URIによる名前付け
- 主語、述語、目的語をURIで名前付けし、識別のスコープをグローバルに
- 組織や領域を超えた連携を可能にする

- 素材としての標準化
- プロパティと値をURIとして正規化=同じものを常に同じ名前で扱う
- グラフを利用した構造正規化で情報を適切に整理する(後述)
- 単純なトリプルに分解することで素材としてアプリケーション処理が容易に
- 素材を標準手段(SPARQL、URI)で利用できることが重要
ジャパンサーチのRDF
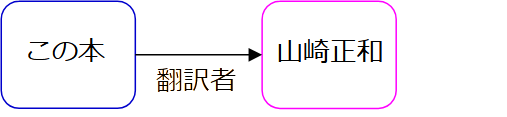
- RDF化の前の段階
- 連携元のデータ:表形式なら一定の構造正規化はされているが、値正規化はまちまち
- 連携フォーマット:基本プロパティ(関係名)の共通マッピング
- 連携フォーマットから利活用スキーマへ
-
- 構造の組み替え:標準モデルに翻訳する。基本的なマッピング
- 埋もれている構造の抽出:値の中に含まれる構造値を切り出す。規則化しにくく処理が複雑(後述)
- 値正規化:典拠と辞書を作りマッピングする。厄介だがやるべきことはストレート
- 型の付与:多様なデータセットの統一利用には必須。基準になる項目がないと大変
値と関係の設計(1):単純値と構造化
- 共通の単純プロパティ
- 同じことを表現する述語は多数。著者、作者、creator…
- 領域ごとに異なるプロパティを共通化。Dublin CoreやSchema.orgの利用。連携フォーマットでもこれを実現
- 一方、単純化するだけでは情報が失われる
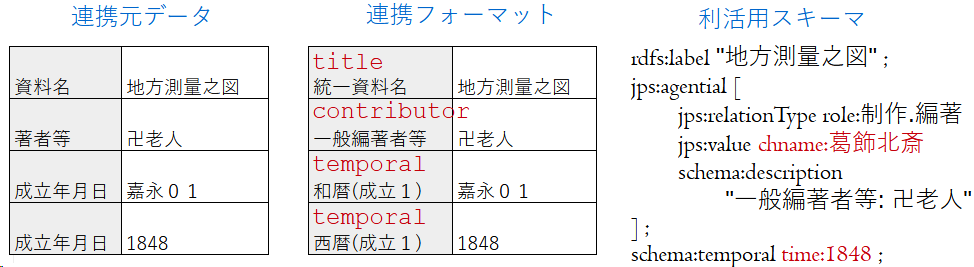
- 正規化と構造化記述
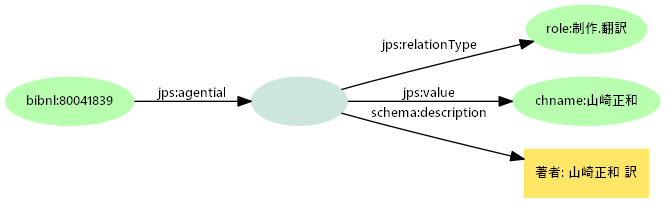
- 情報を構造化し、正規化した値と元の値をセットで記述する
- プロパティの違いも値の役割として構造化する
- プロパティグラフの関係プロパティとして考えてもよい
値と関係の設計(2):利用のバランス
- メンタルモデルはフラット構造?
- 情報がどのような構造で記述されるかは、スキーマを知らないと分からない
- 作者はアイテムの直接プロパティ値か、構造化された記述の値か
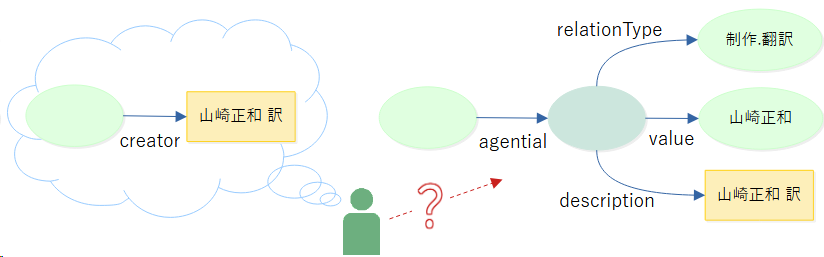
- フラットな記述の想定(メンタルモデル)に対しデータ構造が異なるとうまく利用できない
- ジャパンサーチの二層モデル
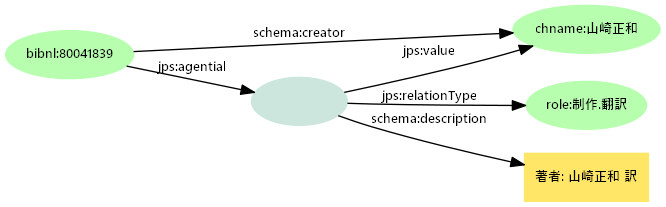
- 単純プロパティと構造化ノードを対で持つ
- タスクによる使い分け:発見タスクなら単純プロパティ、識別/選択タスクなら構造化ノードなど
埋め込まれた構造
- 目次に含まれる記事とタイトル、著者
目次:
思ひつくまゝ(長谷川伸) 新しき批評の登場を望む(千葉亀雄)...- それぞれの記事を独立実体としてタイトル、著者を記述し、雑誌本体とhasPartで関連付ける
:Showa_magazine-100015103 a type:雑誌schema:hasPart[rdfs:label"思ひつくまゝ" ;schema:creatorchname:長谷川伸], [ rdfs:label "新しき批評の登場を望む" ; schema:creator chname:千葉亀雄 ]
- 章節構造の分離と階層化
- 古事類苑データベースの「歳時部十一 1 年始祝三 年玉 774ページ」の構造をグラフで記述
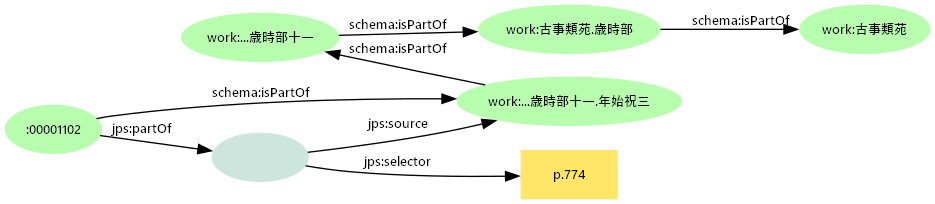
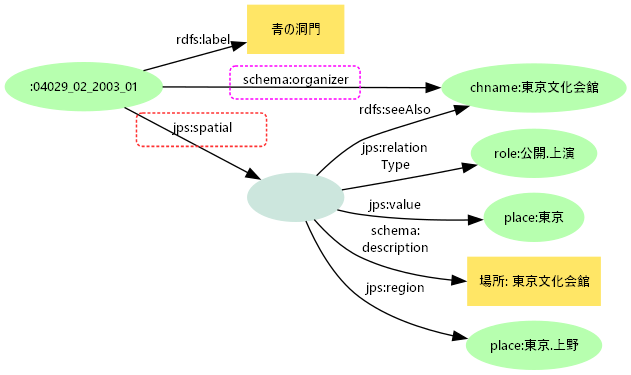
直接目的語と間接ノード
- 場所とそこにある寄与者実体
- 東京文化会館は東京・上野という場所にあるAgent型実体=公演の主体ともなる
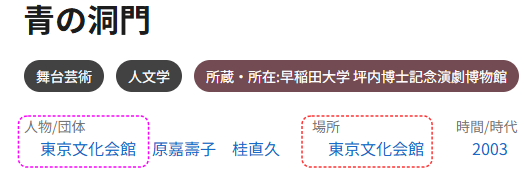
- 連携フォーマットでは「場所」と「上演主体」の値がいずれも東京文化会館
- 場所型寄与実体を間接ノードからのリンクで表現する
- 場所は本来「東京都台東区~」など → 構造化し東京文化会館をrdfs:seeAlsoで関連付ける
ウェブアプリケーションでの利用
- RDFの利点はどのデータも標準手法で利用できること
- クエリ結果はJSONやCSVなどで得られるので、さまざまなウェブアプリケーションで利用可能
SELECT ?prfc (
count(?cho) as ?count) WHERE{ ?cho a type:建築 ; schema:spatial ?prfc . }GROUP BY?prfc- 結果はグラフなどの視覚化も容易。緯度経度や時間情報があれば地図や年表での表示なども可能
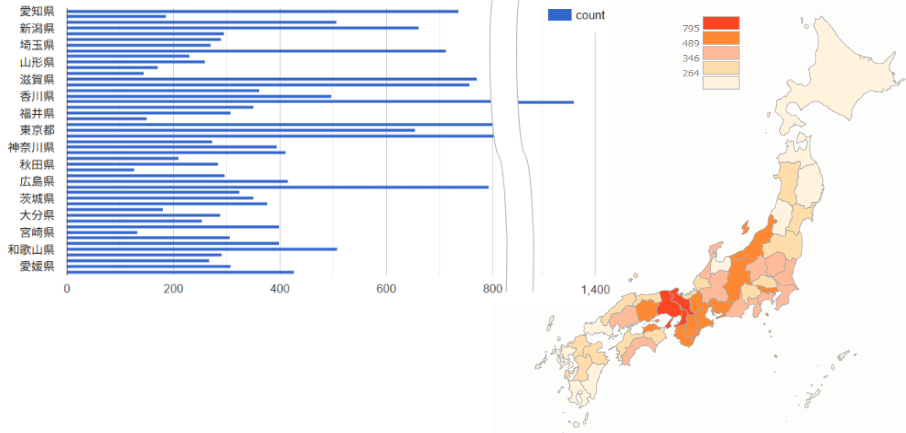
- 一般的APIでもこれらは可能だが、RDFなら標準クエリ言語SPARQLでどこからでも取得できる
異なるデータ種別の連携
- 山崎正和アーカイブの資料種別
- さまざまな種類の情報をグラフとして繋いでいくのがRDFの真骨頂
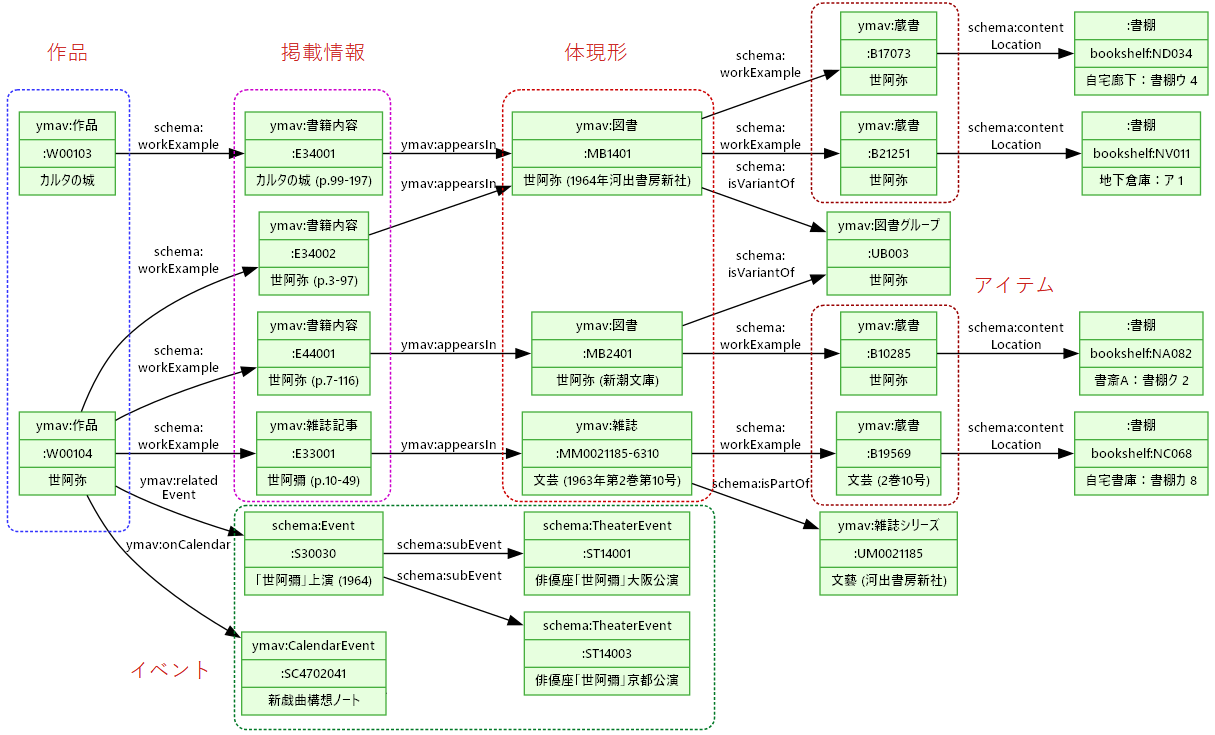
- 作品から蔵書に至るFRBR階層的な情報に加え、上演や手帳記述などのイベント型情報も
- 蔵書データはISBNからNDLサーチを検索してRDFを取得 → 名前正規化などの上でRDF化
- 利活用スキーマをベースに、 書誌(体現形)だけでなく蔵書(アイテム)や著作、イベントも記述する用語を追加
デジタルアーカイブと注釈
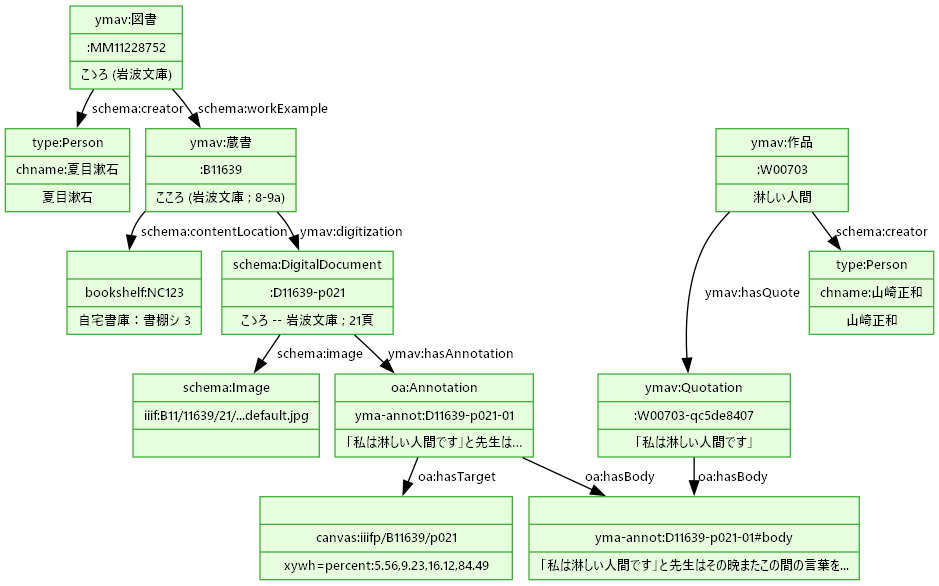
- デジタル化と書き込みの注釈化
- 蔵書のうち書込み/付箋のあるページを選んでデジタル化
- 傍線や書込みの一部を試験的にウェブ注釈モデルで記述しIIIFビューアで表示
- 書き込みによる蔵書から著作へ
- 著作での引用もウェブ注釈モデルで記述し、蔵書から作品へのつながりを表現
RDFと知識グラフ分析
- KGE (Knowledge Graph Embedding)
- RDFなどの知識グラフは複雑な構造になり把握しにくい
- 知識グラフの情報を機械学習で低次元ベクトル空間に埋め込む
- 意味的な情報を保持しながらデータの視覚化や解釈を容易にする
- たとえばWikidata:Embedding ProjectのWikidata Vector Database(まだ日本語は弱い)
- リンク予測を用いて欠落したデータを補完(たとえばtemporalがないアイテムの年代を推定)
- ジャパンサーチRDFでKGEを試す
- 全体の学習は高コスト → 1つのデータセットをPyKEENで学習
- ここでは埼玉県立近代美術館収蔵作品の単純プロパティのみを材料に
- 学習結果からコサイン距離を用いて著者の近傍関係をグラフ化

- 全体の学習は高コスト → 1つのデータセットをPyKEENで学習