
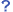

ジャパンサーチ利活用スキーマの人物正規化
ジャパンサーチでの名前正規化
- 要件と目標
- ジャパンサーチ全体をまたぐ一貫した検索・集約
- 利用のしやすさと正確さ(元データ保持)の両立
- ジャパンサーチ内だけでなくの外部との連携
- 正規化の手順
- 基本正規化辞書とデータセットごとの個別辞書を用意
- データセットのマッピング定義で辞書が使えるように値変換
利用しやすさと正確さを両立させるモデル
- 考慮する観点
- 使いやすさ:単純プロパティと統一された名称
- 正確さ:細かなニュアンスの違いの把握、元記述の保存
- 二層モデル
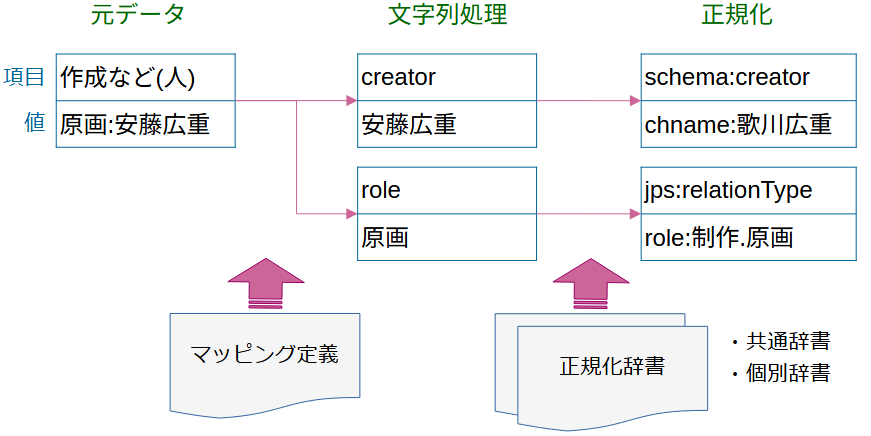
- 直接記述:単純プロパティを期待するメンタルモデル、広く使われるschema.org語彙
- 構造化記述:空白ノードを介して役割や元データをまとめる
- 元データから役割文字と名前を分離し、前者を
relationType、後者をvalueとする
- 元データから役割文字と名前を分離し、前者を
- いずれの記述もURI化した正規化名(あるいはncname)につながる
外部識別子辞書との連携
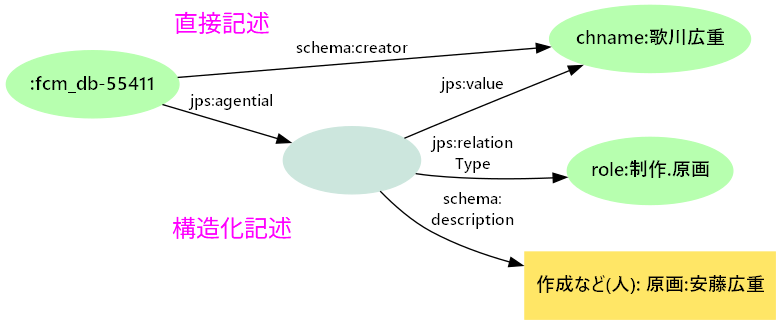
- LODハブを介したつながり
- Wikidata、DBpedia、WebNDLA、VIAFなどとつなぐ → さらに多くの識別子とリンク
- SPARQLでの統合クエリが可能になるなど
- データセットの情報を活かす
- 芳賀人名辞典、メディア芸術DB、APJなど人物情報を定義するIDと関連付ける
- chname:歌川広重―
schema:subjectOf→nij15:00041723 - chname:和田誠―
owl:sameAs→madb:C48061, apj:A2093
- chname:歌川広重―
- chname:正規化名表示時に関連アイテムを列挙する:アイテム付きchname:歌川広重
- 芳賀人名辞典、メディア芸術DB、APJなど人物情報を定義するIDと関連付ける